 Previous |
 Contents |
 Next |
Previous |
Contents |
Next |
The memory strengthens as you lay burdens on it.
— Thomas De Quincey, Confessions of an English Opium-Eater
There’s still room for improvement in the current appointments diary design. Using an array of appointments limits us to a fixed number of appointments; the size of an array must be specified when the array is declared. If the size chosen is too big, memory will be wasted on unused array elements (and the program may or may not run on different machines with different amounts of memory); if it’s too small, the array will get filled up and the user will not be able to add any more appointments.
To solve this problem we need some way of allocating extra memory as and when it is needed. Since this depends on the dynamic behaviour of the program as it is run, this sort of memory allocation scheme is known as dynamic allocation. Ada allows memory to be allocated dynamically like this:
X := new Appointment_Type; -- create a new Appointment_Type record
New takes a free block of memory from a storage pool of available memory (often referred to as a heap) and reserves it for use as an Appointment_Type variable. A reference to its location is then assigned to the variable X so that we then have some way of accessing it. An initial value can be specified for the new appointment like this, assuming that the full declaration of Appointment_Type from the previous chapter is visible:
X := new Appointment_Type'(Time => Time(1999,Dec,25,10,00),
Details => "Open presents ",
Length => 13);
As this example shows, an initial value is specified in parentheses and appended to the type name by an apostrophe ('); this is actually a qualified expression as described in chapter 5.
So how do we declare X in this case? First of all, we need to define an access type (which I’ll call Appointment_Access) and then declare X to be an Appointment_Access variable:
type Appointment_Access is access Appointment_Type; -- the access type
X, Y : Appointment_Access; -- access variables
Variables of type Appointment_Access can only be assigned references to Appointment_Type variables generated by new. In many programming languages variables like this are referred to as pointers since they ‘point to’ a dynamically allocated block of memory, and although this is not official Ada terminology it’s in such widespread use that I’m going to risk offending some language purists by using the terms ‘access value’ and ‘pointer’ interchangeably.
Having set X to point to a dynamically allocated Appointment_Type variable, you can then use ‘X.all’ to access the appointment itself. You can then select components of the appointment in the usual way:
X.all.Time := Time(1995,Dec,25,21,00);
if Month(X.all.Time) = Jan then ...
As a convenience, when you access components of a dynamically allocated record you can just say ‘X.Time’ and so on instead of ‘X.all.Time’:
X.Time := Time(1995,Dec,25,21,00); -- as above
if Month(X.Time) = Jan then ... -- as above
Be careful not to confuse ‘X’ and ‘X.all’; ‘X’ on its own is the name of the access variable, but ‘X.all’ is the value that X points to:
X.all := Y.all; -- copy one appointment into another
X := Y; -- set X to point to the same thing as Y
Assuming that X and Y point to different appointments, the first assignment will copy the contents of one appointment into the other so that you end up with two identical appointments. In the second case X and Y will both end up pointing to the same appointment, and the appointment that X pointed to before is now inaccessible unless there’s another access variable which points to it. After the first assignment, you can alter X.Date and it won’t affect Y.Date since X and Y point to different appointments, but after the second assignment X.Date and Y.Date both refer to the same thing, so any change to X.Date will also be a change to Y.Date.
Apart from assigning a value generated by new to X, you can assign the special value null to X to indicate that it doesn’t point to anything (a ‘null pointer’). Access variables are automatically set to null when they are declared unless new is used to initialise them:
X : Appointment_Access; -- a null pointer
Y : Appointment_Access := null; -- another null pointer
Z : Appointment_Access := new Appointment_Type; -- an initialised pointer
Attempting to access the value that a null pointer points to will generate a constraint error. It’s a good idea to check for null first:
if X = null then ... -- do something sensible if X is null
On the face of it, this doesn’t get us much further since for every dynamically allocated appointment there must still be an access variable which points to it. If all we end up with is an array of access variables instead of an array of appointments we won’t have actually achieved very much!
The solution is to build a linked list of appointments. We need to extend Appointment_Type to include an Appointment_Access value which will be used to point to the next appointment. Then all we need is a single variable to point to the first appointment; the first appointment then points us to the second appointment, which then points us to the third appointment, and so on. It might also be convenient to have a variable which points to the last appointment in the list, but I’ll ignore that possibility for the moment. Here are declarations for types Appt_Type and Appt_Access to handle this:
type Appt_Type; -- 1
type Appt_Access is access Appt_Type; -- 2
type Appt_Type is
record
Time : JE.Times.Time_Type;
Details : String (1..50);
Length : Natural := 0;
Next : Appt_Access; -- 3
end record;
The reason for line 1 in the code above is to resolve the circularity in the declarations of Appt_Type and Appt_Access. The declaration of Appt_Access (line 2) refers to Appt_Type and the declaration of Appt_Type refers to Appt_Access (line 3). Line 1 is an incomplete declaration which simply tells the compiler that Appt_Type is the name of a type of some sort so that the name can be used on line 2 where Appt_Access is declared. If Appt_Type had any discriminants, we’d have to use the following incomplete declaration:
type Appt_Type (<>); -- (<>) means that the type has discriminants
We don’t need to know anything about Appt_Type other than its name in order to declare an access type for it; typically, all access values will occupy the same amount of memory no matter what type of data they point to so that no major burdens are imposed on the compiler. Then, once Appt_Access is declared, we can give the full declaration of Appt_Type which includes an Appt_Access component.
Diary_Type will now contain a pointer to the first appointment in the diary instead of an array of appointments:
type Diary_Type is
record
First : Appt_Access;
Count : Natural := 0;
end record;
Since access values reflect the precise memory location where an appointment has been created it’s no use saving them in a file and expecting them to make any sense when the program is run again, since the actual locations of the appointments will probably be quite different each time the program is run. For this reason it’s unwise to use Ada.Sequential_IO to store Appt_Type values directly; a better way would be to embed the original Appointment_Type from chapter 10 (containing Time, Details and Length) as a component in a larger record which includes the pointer to the next appointment:
type Appointment_Record;
type Appointment_Access is access Appointment_Record;
type Appointment_Record is
record
Appt : Appointment_Type; -- see chapter 10
Next : Appointment_Access;
end record;
The Appt component can then be saved to a file and restored from it, rather than saving and restoring the whole record.
The following diagram illustrates what a list like this will look like:
![]()
The variable First points to the first appointment in the list, which consists of an appointment component Appt and a pointer Next. Next points in turn to the second appointment, and the second appointment’s Next field points to the last appointment. The last appointment in the list does not have an appointment after it, so its Next pointer is set to null to indicate this (symbolised by a diagonal bar in the diagram). We can work through a list of this sort processing each appointment in some way like this:
Current := Diary.First;
while Current /= null loop
Process (Current.Appt);
Current := Current.Next;
end loop;
This assumes that Current is an Appointment_Access variable used to keep track of the current position in the list. Remember, Current.Next and Current.Appt are abbreviations for Current.all.Next and Current.all.Appt.
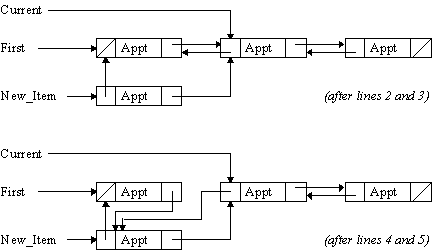
Inserting a new item into the list is quite easy. Given that Current points to an appointment somewhere in the list, here’s how you can insert a new item immediately after that appointment:
New_Item := new Appointment_Record; -- 1
New_Item.Next := Current.Next; -- 2
Current.Next := New_Item; -- 3
The diagrams below illustrates the steps involved:
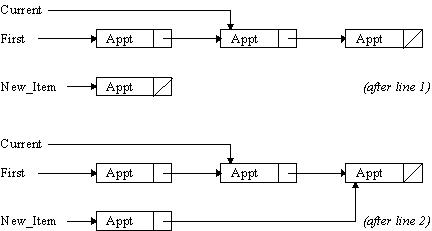
Line 1 creates a new appointment and stores a pointer to it in New_Item, which I’ll assume was declared to be a variable of type Appointment_Access. Line 2 sets its Next field so that the appointment after it is the same appointment that follows Current. Current’s Next pointer is then changed so that the new item is the one after the current item.
Deleting an item is just as easy; the drawback is that to delete a particular item you have to have a pointer to the item before it (since the Next pointer of the item before needs to be altered so that it no longer points to the item being deleted). Assuming that Current points to the item before the one you want to delete, here’s what you have to do:
Current.Next := Current.Next.Next;
In other words, make the item which follows Current be the one after the one that follows it now. The one that follows it now is thus left with nothing pointing to it, and so the memory allocated for it can now be recycled for use elsewhere. I’ll explain how this is done in a moment.
There are a couple of problems here that I’ve glossed over: one of them is inserting an item at the beginning of the list (or into an empty list) rather than after an existing item, and another is deleting the first item in the list. One way to get around these problems is to provide extra procedures to deal with these specific situations, so that you would need two insertion procedures and two deletion procedures. This is not particularly elegant. Another solution would be to use a value of null for the current position to indicate that an item should be inserted before the first item or that the first item should be deleted. Here’s how insertion into a diary called Diary would be done:
New_Item := new Appointment_Record;
if Current /= null then -- insert after another appointment
New_Item.Next := Current.Next;
Current.Next := New_Item;
else -- insert at start of list
New_Item.Next := Diary.First;
Diary.First := New_Item;
end if;
Here’s how deletion would be done:
if Current /= null then -- delete appointment after Current
Current.Next := Current.Next.Next;
else -- delete first appointment
Diary.First := Diary.First.Next;
end if;
The list structure described above is known as a singly linked list, since each item has a single pointer linking it to the next item in the list. This makes it possible to go forwards through the list but not to go backwards. The solution is simple: add another pointer to each item which points to the previous appointment.
type Appointment_Record is
record
Appt : Appointment_Type;
Next : Appointment_Access; -- pointer to next appointment
Prev : Appointment_Access; -- pointer to previous appointment
end record;
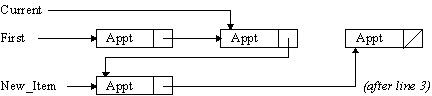
What you now have is a doubly linked list. There will need to be a pointer to both the first and last items in the list so that you can start at either end and traverse the list in either direction. This arrangement makes it much easier to delete appointments. In the case of a singly linked list you have to have a pointer to the item before the one you want to delete; in a doubly linked list the item you want to delete points to its neighbours on each side, so this is what you have to do to delete the item that Current points to:
Current.Prev.Next := Current.Next; -- 1
Current.Next.Prev := Current.Prev; -- 2
In other words, the item before Current is changed to point to the one after Current, and the item after Current is changed to point to the one before Current. The items on either side of Current will therefore bypass it completely. leaving it isolated from the list.
Here’s a diagram showing the initial state of the list:
![]()
The next diagram illustrates what the state of the list is after the two steps above:
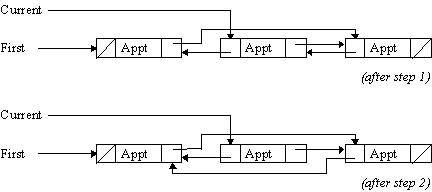
Inserting an appointment into the list involves setting the Prev pointers as well as the Next pointers. This is how you would insert a new appointment in front of the one that Current points to:
New_Item := new Appointment_Record; -- 1
New_Item.Prev := Current.Prev; -- 2
New_Item.Next := Current; -- 3
Current.Prev.Next := New_Item; -- 4
Current.Prev := New_Item; -- 5
This sequence of steps creates a new record (line 1) and links it to the current item and the previous one so that it will appear between the current item and the previous one (lines 2 and 3). The Next pointer of the previous item is then set to point to the new item (line 4), as is the Prev pointer of the current item (line 5).
Here’s a diagram which illustrates what the situation is after the new item has been created by line 1:
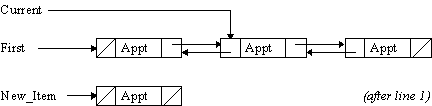
Lines 2 and 3 link the new item to the existing list, and lines 4 and 5 then modify the existing list to include the new item. Here’s a diagram which shows you how it happens:
As with singly linked lists, you can detect the end of the list by the fact that Next contains a null pointer; you can also detect the beginning of the list by the fact that Prev contains a null pointer.
There are several other variations on this theme; for example, it’s sometimes useful to have circular lists where the ends of the list are joined together (i.e. the last item points to the first item and vice versa).
The variable Current that I’ve been using so far could be made into another component of Diary_Type so that each diary would keep track of its own current position for insertion, deletion, etc. A better solution is to define a separate type to represent positions within the list (often called an iterator) which points to the list itself as well as the current position. The advantage of this approach is that you can have more than one ‘current’ position in a single list, and you can save a copy of the iterator for the current position so you can go back to it later. The only problem is when one iterator is used to delete an item that another one is pointing to. Using the second iterator can be catastrophic since the item it points to might not exist any more. There is no easy solution to this; one approach is to keep a count of the number of iterators that are referring to each item, but this is quite complicated to administer and is still not foolproof. The simplest way out is to ignore the problem and just try to avoid getting into such a situation. This is the solution I’m going to adopt here.
Here are the type declarations we need for this approach:
type Appointment_Record;
type Appointment_Access is access Appointment_Record;
type Appointment_Record is
record
Appt : Appointment_Type;
Next : Appointment_Access;
Prev : Appointment_Access;
end record;
type List_Header is
record
First : Appointment_Access;
Last : Appointment_Access;
Count : Natural := 0;
end record;
type List_Access is access List_Header;
type Diary_Type is
record
List : List_Access := new List_Header;
end record;
type Diary_Iterator is
record
List : List_Access;
Current : Appointment_Access;
end record;
The declarations above involve a delicate balancing act. A List_Header contains pointers to the first and last items in the list as well as a count of the number of items in the list. Since access variables can only point to objects created using new, the List pointer in Diary_Iterator can’t point to a List_Header unless the List_Header is created using new. A diary is then just a pointer to a List_Header; this is what the declarations of List_Access and Diary_Type do. When a Diary_Type object is declared, its List component is automatically initialised to point to a newly created List_Header, and an iterator can then point to the same List_Header object. The iterator references the list it’s associated with as well as the current position in the list; I’ll adopt the convention that if the current position is null it means that the iterator is past the end of the list, so that inserting an item when the current position is null will add the item being inserted to the end of the list. When an iterator is declared, its List component will be null which indicates that it isn’t associated with a list; this will need to be checked by the subprograms which operate on iterators.
Now we’ll need some operations to get iterators from a diary and to manipulate them. We can define functions which return iterators pointing to the start of the list and the end of the list (the position after the last item):
function First (Diary : Diary_Type) return Diary_Iterator is
begin
return (List => Diary.List, Current => Diary.List.First);
end First;
function Last (Diary : Diary_Type) return Diary_Iterator is
begin
return (List => Diary.List, Current => null);
end Last;
The names have been chosen to echo the names of the attributes of a discrete type to make them easy to remember. We’ll also need functions to move an iterator forwards or backwards through the list; we can call them Succ and Pred to match the attribute names. These need to check that the iterator is valid (i.e. it points to a list) and that we aren’t trying to go past the end of the list in either direction. We’ll need an Iterator_Error exception which can be raised if anything is wrong:
Iterator_Error : exception;
function Succ (Iterator : Diary_Iterator) return
Diary_Iterator is
begin
if Iterator.List = null or else Iterator.Current = null then
raise Iterator_Error;
else
return (List => Iterator.List,
Current => Iterator.Current.Next);
end if;
end Succ;
function Pred (Iterator : Diary_Iterator) return
Diary_Iterator is
begin
if Iterator.List = null or else
Iterator.Current = Iterator.List.First then
raise Iterator_Error;
elsif Iterator.Current = null then
return (List => Iterator.List,
Current => Iterator.List.Last);
else
return (List => Iterator.List,
Current => Iterator.Current.Prev);
end if;
end Pred;
Both these functions check that Iterator.List isn’t null; Succ also checks that the current position isn’t null (i.e. that we’re not already at the end of the list) and Pred checks that we’re not at the start of the list. Pred also needs to check if the current position is null (i.e. just past the last appointment in the list) and if so set the current position to point to the last appointment.
We’ll also need a function to get the appointment that an iterator points to, and a function to return the length of a list:
function Value (Iterator : Diary_Iterator) return Appointment_Type is
begin
if Iterator.List = null or else Iterator.Current = null then
raise Iterator_Error;
else
return Iterator.Current.Appt;
end if;
end Value;
function Size (Diary : Diary_Type) return Natural is
begin
return Diary.List.Count;
end Size;
These functions can be used to process each appointment in a diary called Diary like this:
declare
I : Diary_Iterator;
begin
I := First(Diary);
while I /= Last(Diary) loop
Process ( Value(I) );
I := Succ(I);
end loop;
end;
There is one remaining detail to be considered, and that is how to deallocate memory allocated using new when you don’t need it any more. If you don’t deallocate it, it will still be there even if you don’t have any way of accessing it any more and you will gradually run out of memory. The memory is only guaranteed to be reclaimed when the access type goes out of scope. If the access type is declared in a library package this won’t happen until after the main program has terminated, which is probably too late to be of any use.
One way to deal with this problem is to keep a free list; that is, a list of items which have been deleted and are free to be used again. All you need to do when you want to delete an item from a list is to detach it from the list and then attach it to the free list instead. When you want to allocate a new item, you just take one from the free list. If the free list is empty, you just use new in the normal way.
The problem with this approach is that your memory usage will only ever increase. If you ever need to allocate an object of a different type using new, there may not be enough free memory available even though you have plenty of ‘free’ memory on your free list. What is needed is a way of telling the system to deallocate the memory so that it can be reused by anything that needs it. The way to do this is to use the standard procedure Ada.Unchecked_Deallocation. As the name implies, there is no check made that the memory is actually free and that you don’t still have an access variable pointing to it; it’s entirely your responsibility to ensure that once you’ve used Unchecked_Deallocation to get rid of something, you never try to refer to it again. If you do the result will be unpredictable and might well crash your program.
Ada.Unchecked_Deallocation is a generic procedure, in just the same way as Ada.Text_IO.Integer_IO is a generic package. Like Ada.Text_IO.Integer_IO, you have to instantiate it before you can use it by specifying what sort of object you’re going to delete with it. Here’s how you do it:
procedure Delete_Appt is new Ada.Unchecked_Deallocation
(Appointment_Type, Appointment_Access);
You need to mention Ada.Unchecked_Deallocation in a with clause before you can do this. What you get out of this is a procedure called Delete_Appt which will deallocate Appointment_Type objects which are pointed to by Appointment_Access values. Delete_Appt takes an Appointment_Access parameter which points to the object you want to delete:
X : Appointment_Access := new Appointment_Type; -- create an appointment
... -- use the appointment
Delete_Appt (X); -- then delete it
We can use this in a procedure to delete an appointment that an iterator is pointing to:
procedure Delete (Iterator : in Diary_Iterator) is
Appt : Appointment_Access;
begin
if Iterator.List = null or else Iterator.Current = null then
raise Iterator_Error;
else
if Iterator.Current.Next = null then
Iterator.List.Last := Iterator.Current.Prev;
else
Iterator.Current.Next.Prev := Iterator.Current.Prev;
end if;
if Iterator.Current.Prev = null then
Iterator.List.First := Iterator.Current.Next;
else
Iterator.Current.Prev.Next := Iterator.Current.Next;
end if;
Appt := Iterator.Current;
Delete_Appt (Appt);
Iterator.List.Count := Iterator.List.Count - 1;
end if;
end Delete;
This procedure needs to check if the appointment being deleted is the first or last one in the list; if not, the pointers in the adjoining appointment records are adjusted, but if it is, the list’s First or Last component must be adjusted instead. Note that the parameter to Delete_Appt is an in out parameter, but Iterator is an unmodifiable in parameter, so we have to copy Iterator.Current into a variable Appt and use Appt as the parameter for Delete_Appt.
To round off the set of operations, we need an Insert procedure to insert a new item in front of the position that an iterator points to:
procedure Insert (Iterator : in Diary_Iterator;
Appt : in Appointment_Type) is
New_Appt : Appointment_Access;
begin
if Iterator.List = null then
raise Iterator_Error;
else
New_Appt := new Appointment_Record;
New_Appt.Next := Iterator.Current;
New_Appt.Appt := Appt;
if Iterator.Current = null then
New_Appt.Prev := Iterator.List.Last;
Iterator.List.Last := New_Appt;
else
New_Appt.Prev := Iterator.Current.Prev;
Iterator.Current.Prev := New_Appt;
end if;
if Iterator.Current = Iterator.List.First then
Iterator.List.First := New_Appt;
else
New_Appt.Prev.Next := New_Appt;
end if;
Iterator.List.Count := Iterator.List.Count + 1;
end if;
end Insert;
This creates a new appointment record which points to the current position as the next appointment after it. There are two special cases to consider. The first is when inserting at the end of the list (i.e. when the current position is null); in this case the appointment needs to be linked to what was the last item in the list and the list’s Last pointer needs adjusting to point to the new appointment. The other is when inserting at the start of the list, in which case the list’s First pointer needs updating.
At this point we can start redesigning JE.Diaries to use a linked list of appointments. Here’s a package specification containing a set of type declarations based on the types I defined above:
with JE.Appointments;
use JE.Appointments;
package JE.Diaries is
type Diary_Type is limited private;
... -- etc.
private
type Appointment_Record;
type Appointment_Access is access Appointment_Record;
type Appointment_Record is
record
Appt : Appointment_Type;
Next : Appointment_Access;
Prev : Appointment_Access;
end record;
type List_Header is
record
First : Appointment_Access;
Last : Appointment_Access;
Count : Natural := 0;
end record;
type List_Access is access List_Header;
type Diary_Type is
limited record
List : List_Access := new List_Header;
end record;
type Diary_Iterator is
record
List : List_Access;
Current : Appointment_Access;
end record;
end JE.Diaries;
The package body will need to provide an instantiation of Ada.Unchecked_Deallocation, so we’ll need a with clause for Ada.Unchecked_Deallocation; the operations on iterators will also need to go into the package body:
with Ada.Sequential_IO, Ada.Unchecked_Deallocation, JE.Times;
package body JE.Diaries is
use JE.Appointments;
package Appt_IO is new Ada.Sequential_IO (Appointment_Type);
procedure Delete_Appt is new Ada.Unchecked_Deallocation
(Appointment_Type, Appointment_Access);
function First (Diary : Diary_Type) return Diary_Iterator is ... ;
function Last (Diary : Diary_Type) return Diary_Iterator is ... ;
function Succ (Iterator : Diary_Iterator) return Diary_Iterator is ... ;
function Pred (Iterator : Diary_Iterator) return Diary_Iterator is ... ;
function Value (Iterator : Diary_Iterator) return Appointment_Type is ... ;
procedure Insert (Iterator : in Diary_Iterator;
Appt : in Appointment_Type) is ... ;
procedure Delete (Iterator : in Diary_Iterator) is ... ;
-- Diary operations declared in package spec go here
end JE.Diaries;
These operations were all defined earlier. It would also be a good idea to put declarations of these operations in the private section of the package specification rather than in the package body; this will prevent client packages from using them but it will allow child packages to use them to navigate through the diary if necessary.
package JE.Diaries is
... -- as before
private
... -- as before
function First (Diary : Diary_Type) return Diary_Iterator;
function Last (Diary : Diary_Type) return Diary_Iterator;
function Succ (Iterator : Diary_Iterator) return Diary_Iterator;
function Pred (Iterator : Diary_Iterator) return Diary_Iterator;
function Value (Iterator : Diary_Iterator) return Appointment_Type;
procedure Insert (Iterator : in Diary_Iterator;
Appt : in Appointment_Type);
procedure Delete (Iterator : in Diary_Iterator);
end JE.Diaries;
Now for the operations on Diary_Type objects. These are very similar to the way they were in the previous chapter. Size is the same as it was before except that it needs to refer to Diary.List.Count instead of Diary.Count:
function Size (Diary : Diary_Type) return Natural is
begin
return Diary.List.Count;
end Size;
Choose is a bit more difficult. It needs to step through the list from the beginning to the requested position:
function Choose (Diary : Diary_Type;
Appt : Positive) return Appointment_Type is
Iterator : Diary_Iterator;
begin
if Appt not in 1 .. Diary.List.Count then
raise Diary_Error;
else
Iterator := First(Diary);
for I in 2 .. Appt loop
Iterator := Succ(Iterator);
end loop;
return Value(Iterator);
end if;
end Choose;
Deleting an appointment also involves stepping through the list to the correct position:
procedure Delete (Diary : in out Diary_Type;
Appt : in Positive) is
Iterator : Diary_Iterator;
begin
if Appt not in 1 .. Diary.List.Count then
raise Diary_Error;
else
Iterator := First(Diary);
for I in 2 .. Appt loop
Iterator := Succ(Iterator);
end loop;
Delete (Iterator);
end if;
end Delete;
Adding an appointment involves locating the correct position for the appointment just like it did with the array implementation. If we’re out of memory a Storage_Error exception will be raised, so this will need to be reported as a Diary_Error:
procedure Add (Diary : in out Diary_Type;
Appt : in Appointment_Type) is
use type JE.Times.Time_Type; -- to allow use of ">"
Iterator : Diary_Iterator;
begin
Iterator := First(Diary);
while Iterator /= Last(Diary) loop
exit when Date(Value(Iterator)) > Date(Appt);
Iterator := Succ(Iterator);
end loop;
Insert (Iterator, Appt);
exception
when Storage_Error =>
raise Diary_Error;
end Add;
Load is very similar to the way it was before, except that it has to make sure the diary is empty by deleting all the appointments in the list rather than just by setting the Count component to zero:
procedure Load (Diary : in out Diary_Type;
From : in String) is
File : Appt_IO.File_Type;
Appt : Appointment_Type;
begin
while Diary.List.Count > 0 loop
Delete (First(Diary));
end loop;
Appt_IO.Open (File, In_File, From);
while not Appt_IO.End_Of_File(File) loop
Appt_IO.Read (File, Appt);
Insert (Last(Diary), Appt);
end loop;
Appt_IO.Close (File);
exception
when Name_Error =>
raise Diary_Error;
end Load;
The diary can be assumed to be saved in date order, so each appointment can be added to the end of the list by using Last(Diary) as the insertion position. Save is also very similar to the previous version, except that it now processes a list of appointments rather than an array of appointments:
procedure Save (Diary : in Diary_Type;
To : in String) is
File : Appt_IO.File_Type;
Iterator : Diary_Iterator := First(Diary);
begin
Appt_IO.Create (File, To);
while Iterator /= Last(Diary) loop
Appt_IO.Write (File, Value(Iterator));
Iterator := Succ(Iterator);
end loop;
Appt_IO.Close (File);
end Save;
The diary program from the previous chapter will not need changing; the visible interface in the package hasn’t been touched, so all the facilities that the program used are still usable in exactly the same way. Only the internal implementation has been affected.
Sometimes it is useful to be able to create pointers to ordinary variables rather than just to objects created using new. Ada refers to such objects as aliased objects since any such object already has a name by which it can be accessed; a pointer to the object acts as an ‘alias’ for it, in other words another name which can be used to access it. To enable the compiler to keep track of which objects are aliased and which ones aren’t, you have to use the reserved word aliased in the object declaration:
I : aliased Integer;
You can also declare aliased array elements and record components:
type Array_Type is array (Positive range <>) of aliased Integer;
type Record_Type is
record
I : aliased Integer;
end record;
Access variables which can be used with aliased objects as well as those allocated using new are declared like this:
type Integer_Access is access all Integer;
The use of access all in the declaration of Integer_Access means that a variable of type Integer_Access is allowed to point to aliased integers like I as well as integers created using new. Integer_Access is known as a general access type as opposed to the pool-specific access types that you’ve seen so far.
You can get a pointer to an aliased variable by using the 'Access attribute:
IA : Integer_Access := I'Access; -- pointer to I (above)
A : Array_Type(1..10); -- see above
AA : Integer_Access := A(5)'Access; -- pointer to A(5)
B : Record_Type; -- see above
BA : Integer_Access := B.I'Access; -- pointer to B.I
There are some limitations placed on this for the sake of safety. The scope of any aliased Integer which IA is going to point to must be at least as large as that of the scope of the type declaration for Integer_Access. This means that the following is illegal in Ada:
procedure Illegal is -- outer scope for declarations
type Integer_Access is access all Integer;
IA : Integer_Access;
begin
...
declare -- inner scope for declarations
I : aliased Integer;
begin
IA := I'Access; -- illegal!
end; -- end of I's scope
IA.all := IA.all + 1; -- eek! I doesn't exist any more!
end Illegal; -- end of Integer_Access's scope
The reason for this is that IA is assigned a pointer to I inside the inner block. At the end of the block, I ceases to exists so that at the point where the assignment statement is executed, IA points to a non-existent variable. This is what is known as a dangling pointer. The restriction may seem a bit severe but it guarantees that any objects that an Integer_Access variable can point to must exist for at least as long as any Integer_Access variable. In particular, if Integer_Access is declared in a library package, the scope of Integer_Access is the entire program so that only variables declared at library level (i.e. declared inside a package which is compiled as a library unit) can be used with Integer_Access. You can get around this to some extent by using generic packages as described in the next chapter, but if the restriction is still too severe you can subvert it by using the attribute 'Unchecked_Access instead of 'Access. As the name implies, no checks on accessibility are performed and it’s up to you to make sure that you don’t do anything stupid:
procedure Legal_But_Stupid is
type Integer_Access is access all Integer;
IA : Integer_Access;
begin
...
declare
I : aliased Integer;
begin
IA := I'Unchecked_Access; -- dangerous!
end;
IA.all := IA.all + 1; -- it's your own fault when
end Legal_But_Stupid; -- this crashes!
Using 'Unchecked_Access is not recommended unless you are completely sure you know what you’re doing!
General access variables must be set to point to variables since they can be used to assign a new value to the object they point to; if you want to point to constants as well as variables you must use access constant instead of access all in the type declaration:
type Constant_Integer_Access is access constant Integer;
A Constant_Integer_Access variable can’t be used to alter the object it points to, whether that object is a constant or a variable. One use for this is to create arrays of strings of different lengths. If you want an array of strings to hold the names of the days of the week the individual strings must all be the same size:
Day_Names : constant array (Day_Of_Week) of String (1..9) :=
("Sunday ", "Monday ", "Tuesday ", "Wednesday",
"Thursday ", "Friday ", "Saturday "); -- all exactly 9 characters long
However, you can have an array of pointers to strings instead, which allows the individual strings to have different lengths:
Sun_Name : aliased constant String := "Sunday";
Mon_Name : aliased constant String := "Monday";
Tue_Name : aliased constant String := "Tuesday";
Wed_Name : aliased constant String := "Wednesday";
Thu_Name : aliased constant String := "Thursday";
Fri_Name : aliased constant String := "Friday";
Sat_Name : aliased constant String := "Saturday";
type Name_Type is access constant String;
Day_Names : array (Day_Of_Week) of Name_Type :=
(Sun_Name'Access, Mon_Name'Access, Tue_Name'Access,
Wed_Name'Access, Thu_Name'Access, Fri_Name'Access,
Sat_Name'Access);
You are also allowed to use the 'Access attribute to create pointers to subprograms:
type Menu_Operation is access procedure;
procedure Add;
procedure List;
procedure Delete;
Menu : constant array (1..3) of Menu_Operation :=
(Add'Access, List'Access, Delete'Access);
type Math_Function is access function (I : Float)
return Float;
function Sin (F : Float) return Float;
function Cos (F : Float) return Float;
function Tan (F : Float) return Float;
Ops : constant array (1..3) of Math_Function :=
(Sin'Access, Cos'Access, Tan'Access);
The number and types of the parameters and the result type of functions must match those given in the access type declaration (but the parameter names don’t need to). Thus a Menu_Operation can point to any parameterless procedure and a Math_Function can point to any function with a single Float parameter and a Float result. You can call these subprograms like this:
Menu(I).all; -- call I'th procedure from array Menu
F := Ops(I)(F); -- call I'th function from array Ops with parameter F
Note that you have to use ‘.all’ to call a parameterless subprogram, but you don’t if there are any parameters; ‘Ops(I)(F)’ is an abbreviation for ‘Ops(I).all(F)’.
The same scope rules apply for pointers to subprograms as for pointers to aliased objects, so that an access procedure type declared in a library package can only point to library-level procedures (i.e. procedures compiled as library units in their own right or procedures inside packages compiled as library units). You can’t use the 'Unchecked_Access attribute with subprograms; to get around this, you have to use generic packages as I mentioned earlier. The way this is done is described in the next chapter.
There are two final features of access types which I’ll describe briefly here but which I’ll come back to in later chapters. An access parameter is a special form of in parameter for a function or procedure:
function F (A : access Integer) return Integer;
procedure G (A : access Integer);
The keyword access is used in place of in, out or in out. The actual parameter you supply when you call a subprogram with an access parameter is any access value which points to the correct type of object:
type Integer_Access is access Integer;
IA : Integer_Access := new Integer'(1);
AI : aliased Integer;
X : Integer := F(IA);
Y : Integer := F(AI'Access);
Z : Integer := F(new Integer);
The parameters to F in the example above are all pointers to an Integer of one sort or another. Within the subprogram the access parameter may be used to inspect or alter the object it points to. The parameter can’t be a null pointer; if it is you’ll get a Constraint_Error when you attempt to call the subprogram. Inside the subprogram the parameter acts like an access value which is a constant (i.e. you can’t alter the pointer itself, although you can alter what it points to) and which belongs to an anonymous access type. Since you haven’t got a name for the access type you can’t declare any more objects of the same type, and any attempts to convert the value to a named access type will be checked to make sure you aren’t breaking the scope rules described earlier for general access types, and a Program_Error exception will be raised if you are.
In a similar way you can use access discriminants in type declarations:
type T (P : access Integer) is
limited record
...
end record;
Any type with an access discriminant must be a limited type, so you can’t use assignment as a way of breaking the scope rules. When you declare an object of type T you must supply an appropriate access value of some sort for the discriminant:
type Integer_Access is access Integer;
Int_Access : Integer_Access := new Integer'(1);
Aliased_Int : aliased Integer;
X : T (Int_Access);
Y : T (Aliased_Int'Access);
Z : T (new Integer);
Again, the discriminant value can’t be null and its type is anonymous so you can’t declare any other objects of the same type.
| 11.1 | Produce a package which implements strings with no maximum size limit. This can be done by allocating space in linked blocks of (say) 100 characters at a time, and linking extra blocks to the end of the existing allocation when more space is needed. Define operations to convert to and from normal strings as well as the standard operations of copying, slicing, concatenating and indexing individual characters. |
| 11.2 | Write a program which asks the user to pick an animal and then tries to identify it by asking a series of yes/no questions (see exercise 3.3). Use a record containing a string and two pointers. If the pointers are null, the string is the name of an animal; if not, the string is a question to ask and the pointers point to further records of the same type, one for a ‘yes’ answer and one for a ‘no’. The program should ask questions and follow the appropriate pointers until an animal’s name (e.g. ‘aardvark’) is reached, at which point the question ‘Is it an aardvark?’ should be asked. If the user responds ‘no’, the program should ask for the name of the animal and a question to distinguish it from an aardvark (or whatever). The question can be used to replace the animal’s name in the last node visited and two extra nodes can be created containing the original animal’s name and the new name entered by the user. |
| 11.3 | Write a procedure to sort a linked list of integers into ascending order. There are lots of ways this could be done! |
| 11.4 | Write a program which counts the number of occurrences of each word typed at the keyboard, as in exercise 6.3, but use a linked list to avoid imposing any limit on the maximum number of words which can be handled. As in exercise 6.3, consider a word to be a sequence of up to 32 letters, and ignore case differences. |
Previous |
Contents |
Next |
This file is part of Ada 95: The Craft
of Object-Oriented Programming by John English.
Copyright © John
English 2000. All rights reserved.
Permission is given to redistribute this work for non-profit educational
use only, provided that all the constituent files are distributed without
change.
$Revision: 1.2 $
$Date: 2001/11/17 12:00:00 $